As I said recently, i18n and l10n are best carried out using the right tools…
I've looked around somewhat and it turns out there seems to be an absolute reference in the area: the GNU gettext framework.
This framework actually comprehends several things:
- A set of conventions about how programs should be written to support i18n;
- A directory and file naming organization for the translated strings;
- A runtime library to display localized text;
- A set of utilities to handle the l10n process;
- A special mode for Emacs which helps preparing the sources for i18n.
Cool beans for the developers...
In a nutshell, here's how it all works:
There's quite a lot to be said about how relevant this system is, but it has quite a few benefits:
- Relative simplicity;
- Pretty good performance (the .MO file include hash tables);
- Integrated conversion between character sets (at least in the spec...);
- And most importantly: the .PO file format has become a de facto standard! This is the real kicker here! You can find a variety of GUI tools for translators to seemlessly work on the PO files: poedit, Gtranslator, KBabel... ;)
Cool beans for the translators...
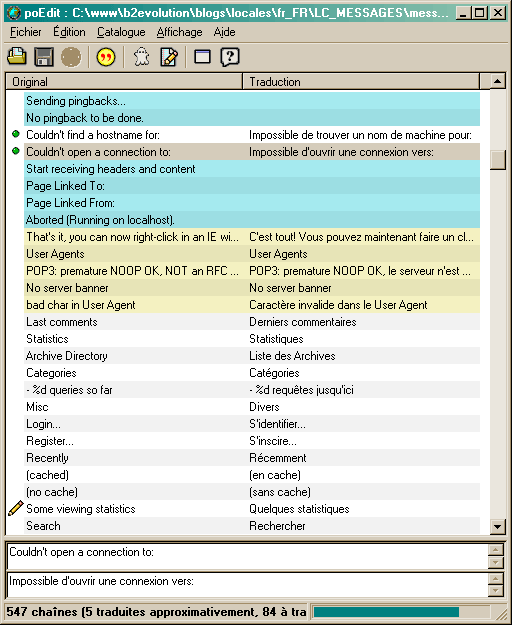
poedit runs on Windows as well as Linux and other Unix OSes. You can see from the screenshot how untranslated strings appear in blue, "fuzzy" translations (the ones you're unsure of and the ones automatically genereated by msgmerge) appear in yellow, and translated strings appear in white.
poedit will also let you add comments or read those the developer may have provided in the .POT file.
And the best of all: poedit will show you all references of a given string in the source code. Even better, it will open the sources and highlight the occurrences for you. This way, you can really make sure what a string is used for when you're not sure about how to translate it! How cool is that again? :D
Actually, I personnaly would have loved some logical module-like grouping of the strings to make usage a little clearer without looking at the sources so often... but hey, the gettext system has enough other advantages for me to forget about this little itch ;)
Comments from long ago:
Comment from: fplanque: /dev/blog
Internationalizing web applications using gettext in PHPAs I have said before, gettext is a very interesting framework for i18n and i10n.
Now the question is, how do I apply this to web applications? Actually, I’m going to restrict my discussion here to PHP since this is what I’m working with right now…
2003-08-20 13-59
Comment from: Pikin
his way, you can really make sure what a string is used for when you’re not sure about how to translate it! How cool is that again?
2006-02-01 16-17